Running an xpresso.ai ML pipeline on Spark¶
ML pipelines on Spark can be run by starting experiments. Each experiment is a run of the pipeline. A typical experiment has the following lifecycle:
Start - when an experiment is started, it generates metrics which can be reported back to xpresso.ai, which stores these in a database for future reference and comparison
Termination - an experiment can be terminated in the middle of execution. This may be required, for instance, if the experiment is not proceeding along the desired path, or is taking too much time, etc.
Completion - when an experiment is completed, it can store its final output in a pre-specified location. xpresso.ai stores this output (typically, a trained model) and tags it with a commit ID, in order to maintain versions of the output. Different experiment runs of the same pipeline can thus result in different versions of the output.
The details for a pipeline deployed on Spark are provided below.
Pipeline Lifecycle on Spark
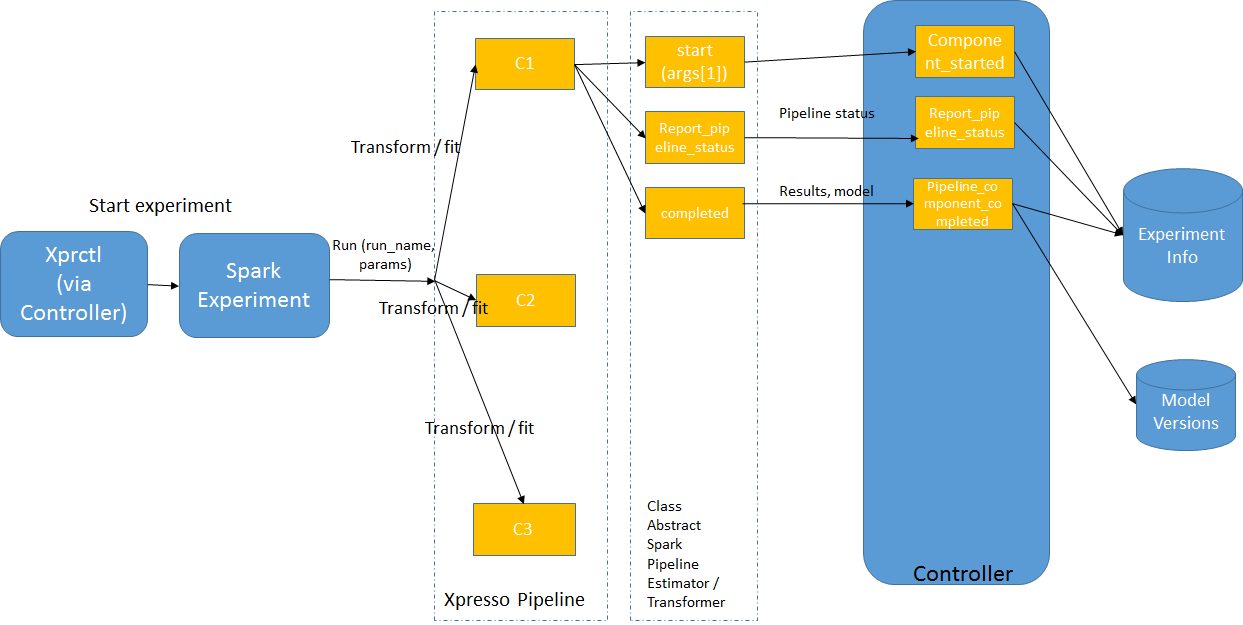
Fig. 1: ML Pipeline lifecycle on Spark
The typical ML pipeline lifecycle on Spark is displayed in Fig. 1.
Notes:
ML pipelines on Spark are run in a very different manner than on Kubeflow. In Spark, each pipeline is run as a monolithic piece of code (unlike Kubeflow, where each component of the pipeline is run individually) - see https://spark.apache.org/docs/latest/ml-pipeline.html for details.
The Spark pipeline may be run from within a Docker image (if Kubernetes is used as the cluster resource manager), or directly from the Python code (if YARN is used as the cluster resource manager). This detail is hidden from developers - the pipeline coding, build and deployment process is exactly the same in both cases.
When an experiment is run, the entry point object is run with the parameters provided by the user in the experiment start instructions as arguments (augmented with the run name as the first parameter).
The developer must create this entry-point class. The main method of this class typically does the following:
Performs initializations (gets the run ID and initializes the Spark session) - in future versions, this functionality will be handled by the xpresso.ai base classes
Creates the pipeline stage array. Just as in standard Spark ML pipelines, an xpresso.ai Spark ML pipeline array consists of Estimators and Transformers.
Estimator classes should inherit from two base classes:
any Estimator class present in the Spark ML library (e.g., pyspark.ml.feature.StringIndexer)
the xpresso.ai AbstractSparkPipelineEstimator class
Transformer classes should inherit from two base classes:
any Transformer class present in the Spark ML library (e.g., pyspark.ml.feature.VectorAssembler)
the xpresso.ai AbstractSparkPipelineTransformer class
Creates an XprPipeline object using the stage array created above
Runs the pipeline - typically this consists of running the fit method of the pipeline to “train” the pipeline and create a “model”, followed by the transform method on the “model” to get the final output.
Runs any further validations required (e.g., validating the model on some data)
Stops the Spark session
Lifecycle Stages
1. Start Experiment
The Start Experiment process has been described above
2. Component Processing Logic
The processing logic of each component is unconstrained - developers can code this logic as per their requirements. The only constraint is as follows:
processing logic for any Estimator components should be in a fit method
processing logic for any Transformer components should be in a transform method
The following actions, which are expected of the component in a Kubeflow pipeline, are not supported in a Spark pipeline:
saving the state and restoring
reporting component status and metrics on a periodic basis
Consequently, pause and restart are not supported. Status is not supported on as granular basis as it is in Kubeflow pipelines. This is because of the distributed manner in which Spark runs the components. Since the components may run on different executor nodes, it is difficult to coordinate status reporting, and state save / load activities.
3. Normal Pipeline Completion
On completion of the component processing logic, the XprPipeline class reports the final status and stores the final model in the model versioning system.
4. Handling Asynchronous Interrupts
As mentioned above, asynchronous interrupts (pause / terminate) are not supported on Spark pipelines, and will be ignored. Restart requests for an experiment will result in a new run of the experiment.