Architecture¶
The high-level architecture of xpresso.ai is shown in the figure below
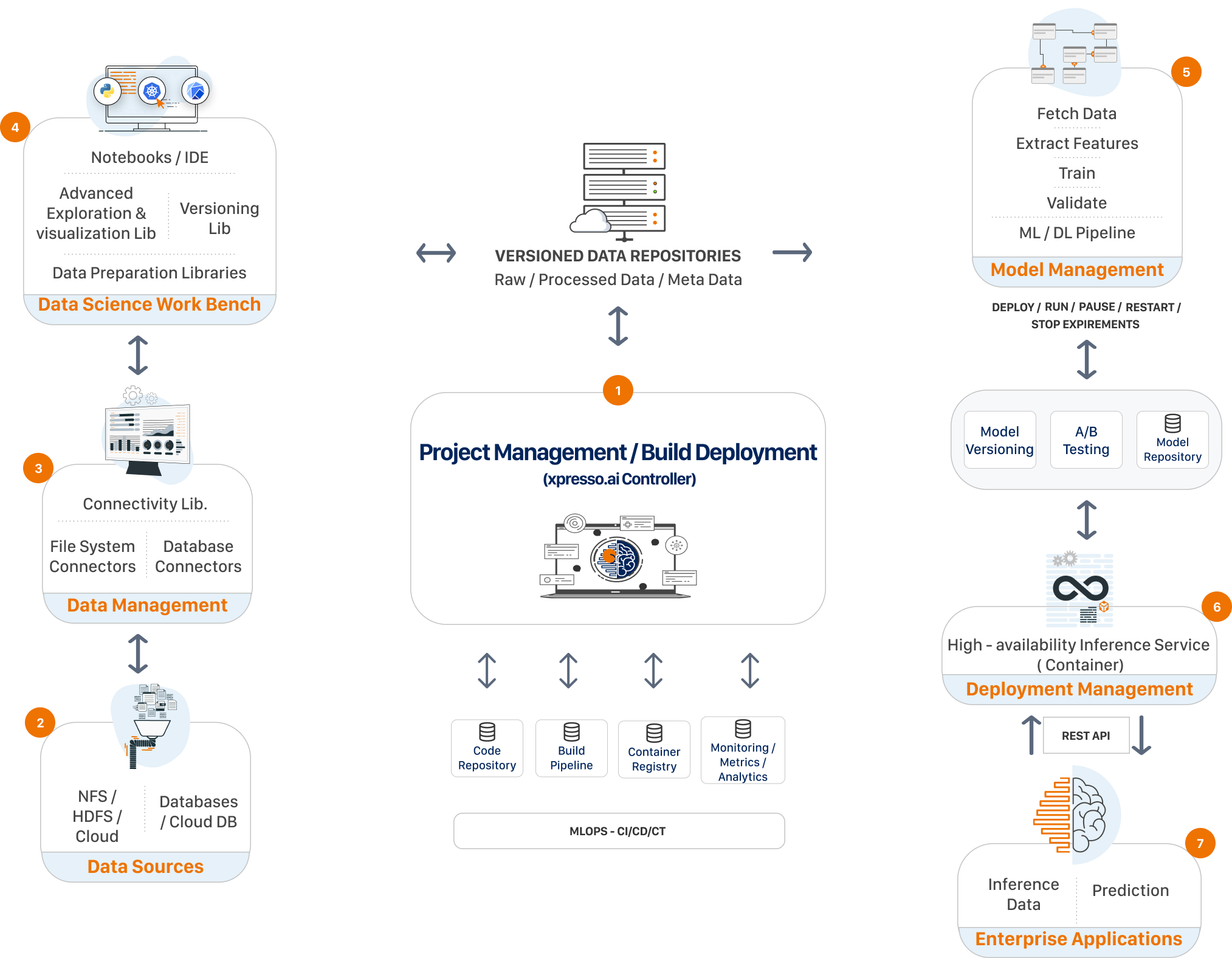
xpresso.ai essentially consists of two parts:
Data Management Libraries
Infrastructure for managing the entire lifecycle of analytics solutions development
Data Management Libraries
xpresso.ai provides python libraries enabling developers to:
Import data from various kinds of data sources (e.g., local / remote / cloud file systems, RDBMS, NOSQL databases, etc.)
Explore data using univariate and bivariate analysis techniques
Clean data by performing standard data cleansing operations
Visualize exploration results using standard graphics libraries, and export visualization results into well-formatted reports
Version data by pushing it into the xpresso.ai Data Repository
Analytics Solution Development Infrastructure
The xpresso.ai Solution Development infrastructure consists of the following components. It can be installed on-premise, or on any public cloud. When installed on the popular public cloud environments (AWS, Azure and GCP), xpresso.ai can make use of services provided by the specific cloud vendor to replace some of the components mentioned below:
Control and Governance
xpresso.ai Controller - the controller orchestrates the entire `solution development workflow. It provides APIs to authorized clients to perform functions such as creating solutions, adding components to solutions, building and deploying components, running experiments, etc.
xpresso.ai Control Center - the Control Center provides an intuitive GUI for developers to instruct the Controller to perform various solution development actions
Authentication Service - xpresso.ai can connect to various authentication services, e.g., LDAP, Active Directory, etc. By default, each xpresso.ai installation has an OpenLDAP server for authentication. This can be re-configured to suit the needs of the installation.
Data Ops
Data Repository - the xpresso.ai Data Repository enables developers to version their data. Developers can create branches in the repository, and upload and download data into branches using the GUI, or python libraries.
Shared File System - xpresso.ai provides shared file systems to enable developers working on the same project to share data and configuration files. Both NFS and HDFS shares are available. Developers are provided standard mount paths on the shared file systems, so that they can use these mount paths within their code.
Dev Ops
Code Repository - xpresso.ai can link to various code repositories supporting the git protocol, such as Bitbucket, GitLab, etc. These repositories can be on-premise or cloud-based.
Build Pipeline - xpresso.ai uses Jenkins as the automation server, and provides pre-configured build pipelines for each component in a solution. By default, each build pipeline automatically checks out the latest code from a specified branch of the code repository, compiles the code, runs unit / system tests, and finally, creates a Docker image and stores it in the container registry.
Container Registry - this stores Docker images of each version of each component built using the xpresso.ai Build pipeline.
Deployment Cluster - xpresso.ai supports various deployment options:
Services of various kinds can be deployed to Kubernetes clusters
Jobs of various kinds can be deployed to Kubernetes or Spark clusters (Spark support in xpresso.ai can use either YARN or Kubernetes as the Resource Manager)
Pipelines (e.g. model training pipelines or ETL pipelines) can be deployed to Kubeflow or Spark clusters.
Model Ops
Model Repository - the xpresso.ai Model Repository stores models created by training pipelines. Developers can create branches in the repository, and download models into branches using the GUI, or python libraries.