Deploying trained models¶
Deploying a trained model creates a REST API end point for it, which can be used to send requests to the model and get predictions.
To do this, the selected model has to be wrapped within an Inference Service
An Inference Service is a special form of a web service customized to query a trained model and return a prediction from it. You can deploy one or more trained models at a time. Each must be coupled with an Inference Service.
To deploy one or more trained models, click the “Deploy Model” button on the “Model Repository” page (see below). (To get to this page, refer to these instructions )
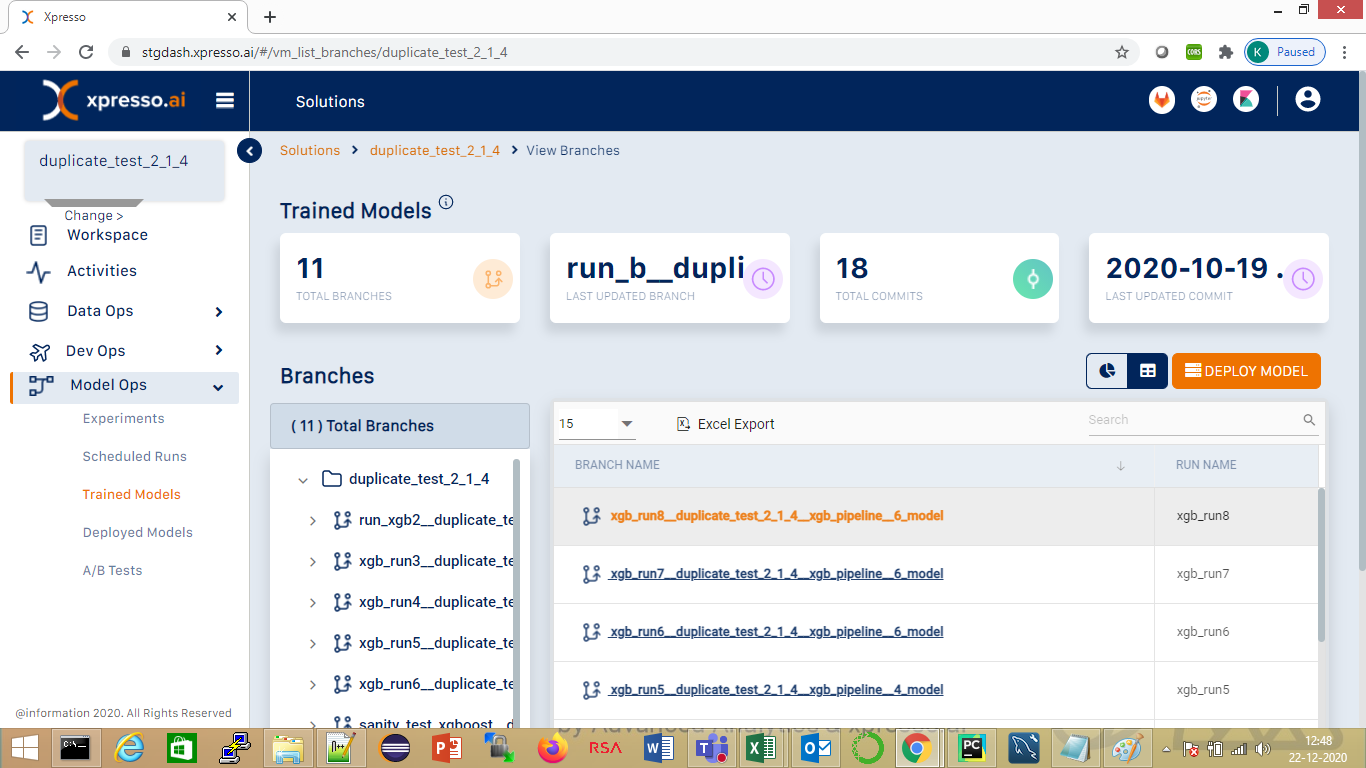
This opens the “Deploy Model” page (see below)
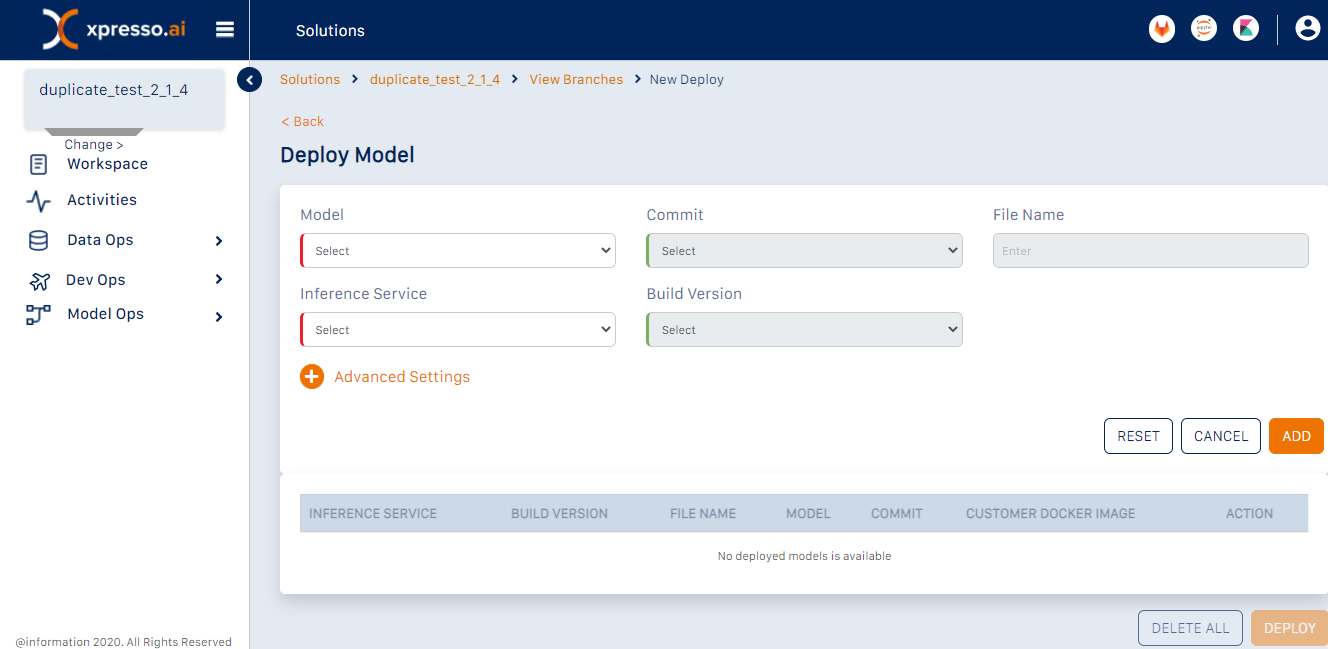
This page enables you to deploy one or more trained models. For each model that you want to deploy, you must do the following
Select the trained model to be deployed. (Since each trained model is the output of a successful experiment run, you are essentially selecting an experiment run in this step)
Select the commit ID of the model - the name of the model file / folder will be automatically displayed
Select the Inference Service to be coupled with the trained model from a list of Inference Servies available in the solution. Ensure that the seected Inference Service is compatibe with the model selected
Select the Build Version of the Inference Service
Specify any Advanced Settings by expanding the “Advanced Settings” section (see below)
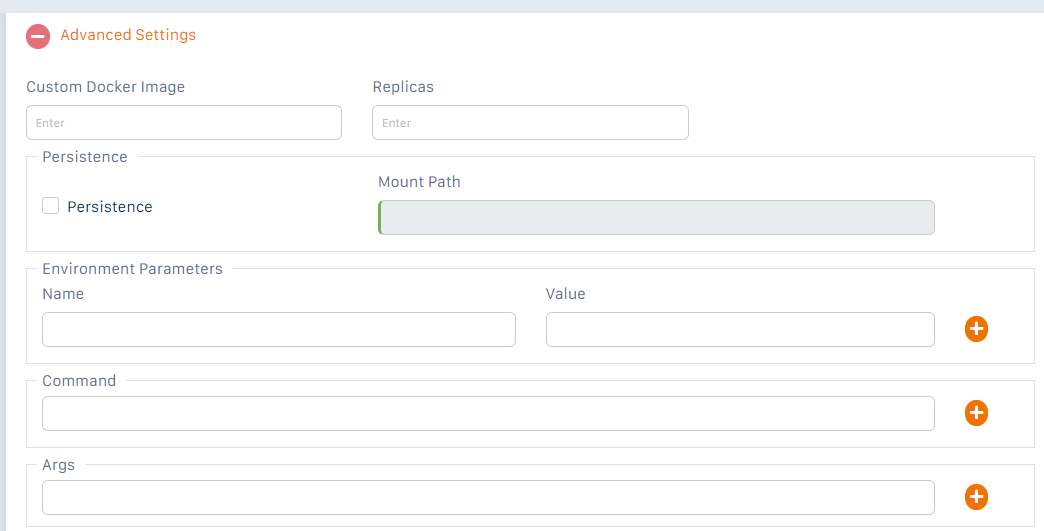
The Advanced settings are the same those used when you deploy a service component
CLick the “Add” button - this will add the model selected to the list of models to be deployed in the table below.
Follow the above process to add more models to be deployed. When you are done, click “Submit” to deploy the model(s)
What do you want to do next?