Experiment Workflow¶
An Experiment is one of the main tools provided by xpresso.ai for Data Scientists. Hence, it is important to understand the typical workflow of an experiment, as depicted below
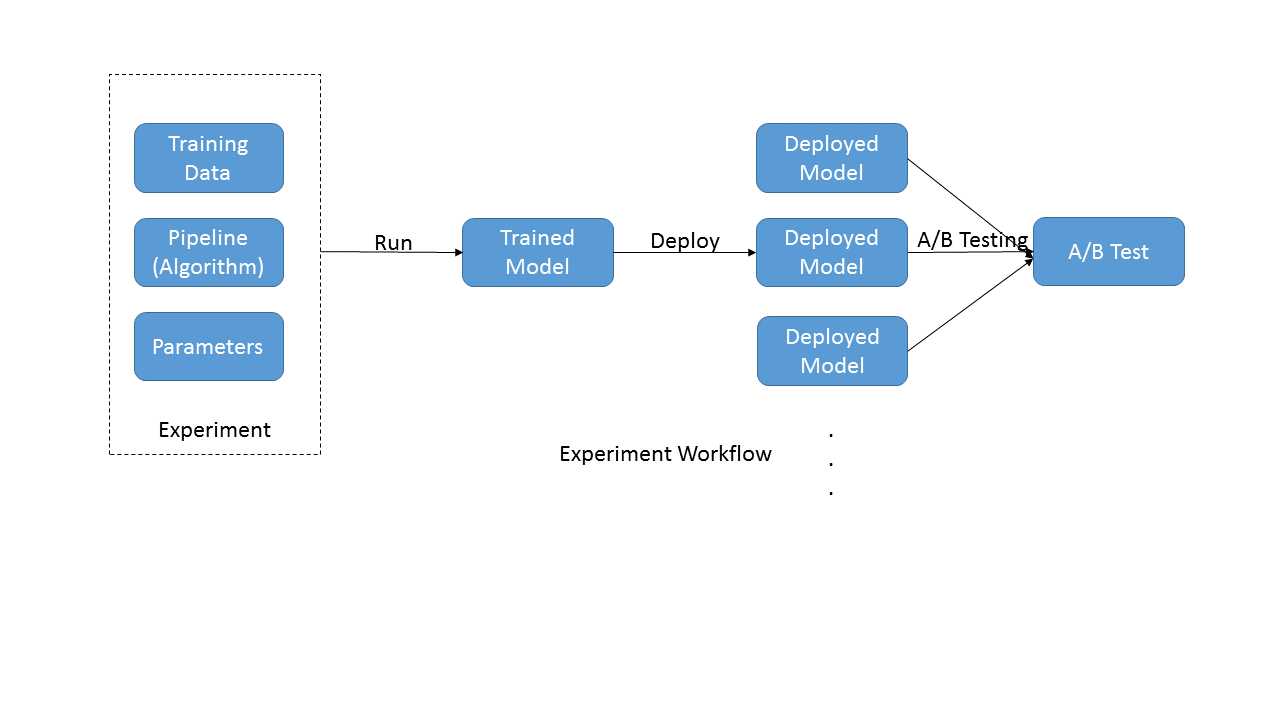
The purpose of running an experiment is typically to train a model, and the output of the experiment is the trained model.
An experiment run has three inputs, each of which the Data Scientist can control:
The Training Data - this is typically fetched from the data repository . The Data Scientists needs to select the correct data version for the experiment
The Training Pipeline - this consists of a set of steps for fetching data, cleaning it, extracting features and finally, training and evaluation. xpresso.ai maintains pipeline versions in its database. The Data Scientist needs to select the correct pipeline version for the experiment.
The Training Parameters (also called Hyperparameters) - these are typically used to control the training algorithm. xpresso.ai pipelines accept parameters through a JSON file, typically stored on the shared file system. When an experiment is run, this parameters file is automatically checked into xpresso.ai’s data repository.
The output of an experiment is a trained model. This is also stored by xpresso.ai in the Model Repository.
Thus, after a successful experiment run, all the inputs (training data, pipeline and parameters) are versioned and stored in repositories. In addition, the output trained model is also stored in the Model Repository.
Once the trained model is available, it can be **deployed** for making predictions. To do this, the Data Scientist creates an Inference Service, points it to one of the models in the Model Repository, and deploys the service. This creates an end point for a REST API which can be used to send requests to the deployed model and receive predictions.
Once two or more models have been deployed, Data Scientists can run **A/B Tests** on them. Data Scientists select the models to be tested, and create an A/B Test around them. xpresso.ai will set up an end point which will route requests among the models involved, according to a routing strategy specified by the Data Scientist. The predictions returned include information about the model used for the prediction, ths enabling the Data Scientist to understand which models are performing better than others.
What do you want to do next?